GPGPU
General-Purpose computing on
Graphics Processor Units
Why should I bother GPU?
Moore is no more
Real parallel computation
Available for normal people
Applications
- Graphics
- Simulations
- AI
- Data Analysis
“Talk is cheep show me the code”
Linus Torvalds
Add the corresponding locations of
A and B, and store the result in C.
Plain Old C
void vecadd( int *A , int *B , int *C)
{
for (int i = 0; i < L; i++) {
C[i] = A[i] + B[i];
}
}
OpenMP
void vecadd( int *A , int *B , int *C)
{
chunk = CHUNKSIZE;
#pragma omp parallel shared(A,B,C,chunk) private(i)
{
#pragma omp for schedule(dynamic,chunk) nowait
for (int i = 0; i < L; i++) {
C[i] = A[i] + B[i];
}
}
}
GLSL
#version 110
uniform sampler2D texture1;
uniform sampler2D texture2;
void main() {
vec4 A = texture2D(texture1, gl_TexCoord[0].st);
vec4 B = texture2D(texture2, gl_TexCoord[0].st);
gl_FragColor = A + B;
}
OpenCL
__kernel
void vecadd(__global int *A,
__global int *B,
__global int *C)
{
int id = get_global_id(0);
C[id] = A[id] + B[id];
}
CUDA
__global__
void vecadd( int *A , int *B , int *C)
{
int id = blockIdx.x*blockDim.x+threadIdx.x;
C[id] = A[id] + B[id] ;
}
Not so fast
- Copy data to GPU
- Launch kernel
- Check for errors
- Copy output back to RAM
Results
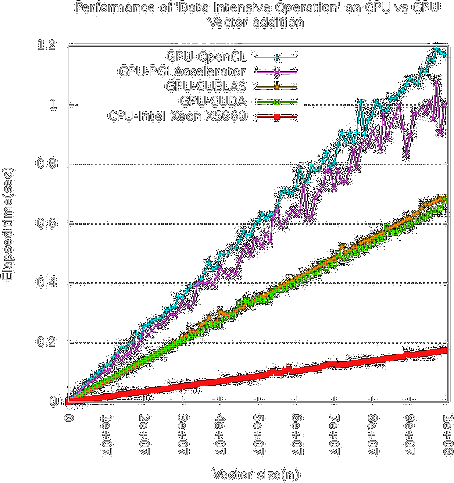
http://hpclab.blogspot.com/2011/09/is-gpu-good-for-large-vector-addition.html
but for harder problems

http://hpclab.blogspot.com/2011/09/is-gpu-good-for-large-vector-addition.html
How it works inside?
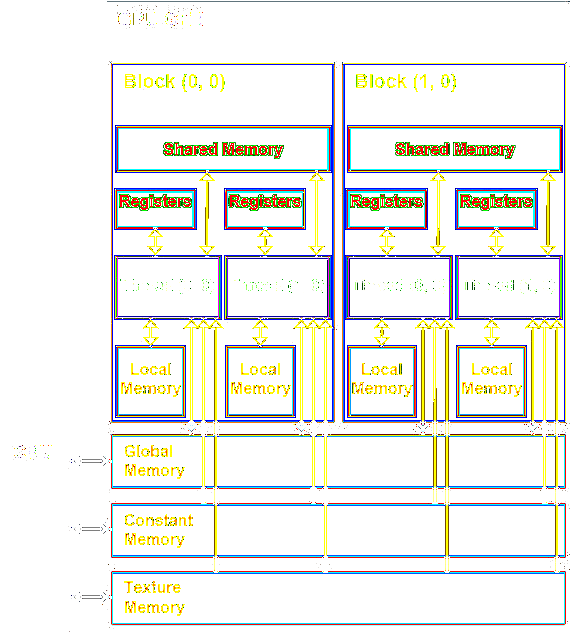
Rules Of Thumb
RTFM
“Life is too short for man pages, and occasionally much too short without them.”
Randall Munroe (xkcd.com)
Think parallel
SIMD
Problems
Problem: Development is hard
Solution: Always have spare GPU in your computer
Problem: Debugging is impossible
Solution: Write tests and run them!
Problem: Copying data to/from GPU is slow
Solution: Use stream and compute while data are loaded
Problem: GPU doesn't like 64bit computation
Solution: Wait for next release
Problem: I dont want to code a lot
Solution: Use libs
- ArrayFire
- Thrust (STL for CUDA)
- cuBLAS (Basic Linear Algebra Subprograms)
- cuFFT
- cuDNN (GPU-accelerated library of primitives for deep neural networks)
Before you code your custom solution.
PGStorm
postgres=# SELECT COUNT(*) FROM t1 WHERE sqrt((x-25.6)^2 + (y-12.8)^2) < 15;
count
-------
6718
(1 row)
Time: 7019.855 ms
postgres=# SELECT COUNT(*) FROM t2 WHERE sqrt((x-25.6)^2 + (y-12.8)^2) < 15;
count
-------
6718
(1 row)
Time: 176.301 ms
t1 and t2 contain same contents with 10 millions of records,
but t1 is a regular table and t2 is a foreign table managed by PG-Strom